
Agents SDK v0.3.0, workers-ai-provider v3.0.0, and ai-gateway-provider v3.0.0 with AI SDK v6 support
We've shipped a new release for the Agents SDK ↗ v0.3.0 bringing full compatibility with AI SDK v6 ↗ and introducing the unified tool pattern, dynamic tool approval, and enhanced React hooks with improved tool handling.
This release includes improved streaming and tool support, dynamic tool approval (for "human in the loop" systems), enhanced React hooks with
onToolCallcallback, improved error handling for streaming responses, and seamless migration from v5 patterns.This makes it ideal for building production AI chat interfaces with Cloudflare Workers AI models, agent workflows, human-in-the-loop systems, or any application requiring reliable tool execution and approval workflows.
Additionally, we've updated workers-ai-provider v3.0.0, the official provider for Cloudflare Workers AI models, and ai-gateway-provider v3.0.0, the provider for Cloudflare AI Gateway, to be compatible with AI SDK v6.
AI SDK v6 introduces a unified tool pattern where all tools are defined on the server using the
tool()function. This replaces the previous client-sideAIToolpattern.TypeScript import { tool } from "ai";import { z } from "zod";// Server: Define ALL tools on the serverconst tools = {// Server-executed toolgetWeather: tool({description: "Get weather for a city",inputSchema: z.object({ city: z.string() }),execute: async ({ city }) => fetchWeather(city)}),// Client-executed tool (no execute = client handles via onToolCall)getLocation: tool({description: "Get user location from browser",inputSchema: z.object({})// No execute function}),// Tool requiring approval (dynamic based on input)processPayment: tool({description: "Process a payment",inputSchema: z.object({ amount: z.number() }),needsApproval: async ({ amount }) => amount > 100,execute: async ({ amount }) => charge(amount)})};TypeScript // Client: Handle client-side tools via onToolCall callbackimport { useAgentChat } from "agents/ai-react";const { messages, sendMessage, addToolOutput } = useAgentChat({agent,onToolCall: async ({ toolCall, addToolOutput }) => {if (toolCall.toolName === "getLocation") {const position = await new Promise((resolve, reject) => {navigator.geolocation.getCurrentPosition(resolve, reject);});addToolOutput({toolCallId: toolCall.toolCallId,output: {lat: position.coords.latitude,lng: position.coords.longitude}});}}});Key benefits of the unified tool pattern:
- Server-defined tools: All tools are defined in one place on the server
- Dynamic approval: Use
needsApprovalto conditionally require user confirmation - Cleaner client code: Use
onToolCallcallback instead of managing tool configs - Type safety: Full TypeScript support with proper tool typing
Creates a new chat interface with enhanced v6 capabilities.
TypeScript // Basic chat setup with onToolCallconst { messages, sendMessage, addToolOutput } = useAgentChat({agent,onToolCall: async ({ toolCall, addToolOutput }) => {// Handle client-side tool executionawait addToolOutput({toolCallId: toolCall.toolCallId,output: { result: "success" }});}});Use
needsApprovalon server tools to conditionally require user confirmation:TypeScript const paymentTool = tool({description: "Process a payment",inputSchema: z.object({amount: z.number(),recipient: z.string()}),needsApproval: async ({ amount }) => amount > 1000,execute: async ({ amount, recipient }) => {return await processPayment(amount, recipient);}});The
isToolUIPartandgetToolNamefunctions now check both static and dynamic tool parts:TypeScript import { isToolUIPart, getToolName } from "ai";const pendingToolCallConfirmation = messages.some((m) =>m.parts?.some((part) => isToolUIPart(part) && part.state === "input-available",),);// Handle tool confirmationif (pendingToolCallConfirmation) {await addToolOutput({toolCallId: part.toolCallId,output: "User approved the action"});}If you need the v5 behavior (static-only checks), use the new functions:
TypeScript import { isStaticToolUIPart, getStaticToolName } from "ai";The
convertToModelMessages()function is now asynchronous. Update all calls to await the result:TypeScript import { convertToModelMessages } from "ai";const result = streamText({messages: await convertToModelMessages(this.messages),model: openai("gpt-4o")});The
CoreMessagetype has been removed. UseModelMessageinstead:TypeScript import { convertToModelMessages, type ModelMessage } from "ai";const modelMessages: ModelMessage[] = await convertToModelMessages(messages);The
modeoption forgenerateObjecthas been removed:TypeScript // Before (v5)const result = await generateObject({mode: "json",model,schema,prompt});// After (v6)const result = await generateObject({model,schema,prompt});While
generateObjectandstreamObjectare still functional, the recommended approach is to usegenerateText/streamTextwith theOutput.object()helper:TypeScript import { generateText, Output, stepCountIs } from "ai";const { output } = await generateText({model: openai("gpt-4"),output: Output.object({schema: z.object({ name: z.string() })}),stopWhen: stepCountIs(2),prompt: "Generate a name"});Note: When using structured output with
generateText, you must configure multiple steps withstopWhenbecause generating the structured output is itself a step.Seamless integration with Cloudflare Workers AI models through the updated workers-ai-provider v3.0.0 with AI SDK v6 support.
Use Cloudflare Workers AI models directly in your agent workflows:
TypeScript import { createWorkersAI } from "workers-ai-provider";import { useAgentChat } from "agents/ai-react";// Create Workers AI model (v3.0.0 - enhanced v6 internals)const model = createWorkersAI({binding: env.AI,})("@cf/meta/llama-3.2-3b-instruct");Workers AI models now support v6 file handling with automatic conversion:
TypeScript // Send images and files to Workers AI modelssendMessage({role: "user",parts: [{ type: "text", text: "Analyze this image:" },{type: "file",data: imageBuffer,mediaType: "image/jpeg",},],});// Workers AI provider automatically converts to proper formatEnhanced streaming support with automatic warning detection:
TypeScript // Streaming with Workers AI modelsconst result = await streamText({model: createWorkersAI({ binding: env.AI })("@cf/meta/llama-3.2-3b-instruct"),messages: await convertToModelMessages(messages),onChunk: (chunk) => {// Enhanced streaming with warning handlingconsole.log(chunk);},});The ai-gateway-provider v3.0.0 now supports AI SDK v6, enabling you to use Cloudflare AI Gateway with multiple AI providers including Anthropic, Azure, AWS Bedrock, Google Vertex, and Perplexity.
Use Cloudflare AI Gateway to add analytics, caching, and rate limiting to your AI applications:
TypeScript import { createAIGateway } from "ai-gateway-provider";// Create AI Gateway provider (v3.0.0 - enhanced v6 internals)const model = createAIGateway({gatewayUrl: "https://gateway.ai.cloudflare.com/v1/your-account-id/gateway",headers: {"Authorization": `Bearer ${env.AI_GATEWAY_TOKEN}`}})({provider: "openai",model: "gpt-4o"});The following APIs are deprecated in favor of the unified tool pattern:
Deprecated Replacement AITooltypeUse AI SDK's tool()function on serverextractClientToolSchemas()Define tools on server, no client schemas needed createToolsFromClientSchemas()Define tools on server with tool()toolsRequiringConfirmationoptionUse needsApprovalon server toolsexperimental_automaticToolResolutionUse onToolCallcallbacktoolsoption inuseAgentChatUse onToolCallfor client-side executionaddToolResult()Use addToolOutput()- Unified Tool Pattern: All tools must be defined on the server using
tool() convertToModelMessages()is async: Addawaitto all callsCoreMessageremoved: UseModelMessageinsteadgenerateObjectmode removed: RemovemodeoptionisToolUIPartbehavior changed: Now checks both static and dynamic tool parts
Update your dependencies to use the latest versions:
Terminal window npm install agents@^0.3.0 workers-ai-provider@^3.0.0 ai-gateway-provider@^3.0.0 ai@^6.0.0 @ai-sdk/react@^3.0.0 @ai-sdk/openai@^3.0.0- Migration Guide ↗ - Comprehensive migration documentation from v5 to v6
- AI SDK v6 Documentation ↗ - Official AI SDK migration guide
- AI SDK v6 Announcement ↗ - Learn about new features in v6
- AI SDK Documentation ↗ - Complete AI SDK reference
- GitHub Issues ↗ - Report bugs or request features
We'd love your feedback! We're particularly interested in feedback on:
- Migration experience - How smooth was the upgrade from v5 to v6?
- Unified tool pattern - How does the new server-defined tool pattern work for you?
- Dynamic tool approval - Does the
needsApprovalfeature meet your needs? - AI Gateway integration - How well does the new provider work with your setup?
Earlier this year, we announced the launch of the new Terraform v5 Provider. We are aware of the high number of issues reported by the Cloudflare community related to the v5 release. We have committed to releasing improvements on a 2-3 week cadence ↗ to ensure its stability and reliability, including the v5.15 release. We have also pivoted from an issue-to-issue approach to a resource-per-resource approach ↗ - we will be focusing on specific resources to not only stabilize the resource but also ensure it is migration-friendly for those migrating from v4 to v5.
Thank you for continuing to raise issues. They make our provider stronger and help us build products that reflect your needs.
This release includes bug fixes, the stabilization of even more popular resources, and more.
- ai_search: Add AI Search endpoints (6f02adb ↗)
- certificate_pack: Ensure proper Terraform resource ID handling for path parameters in API calls (081f32a ↗)
- worker_version: Support
startup_time_ms(286ab55 ↗) - zero_trust_dlp_custom_entry: Support
upload_status(7dc0fe3 ↗) - zero_trust_dlp_entry: Support
upload_status(7dc0fe3 ↗) - zero_trust_dlp_integration_entry: Support
upload_status(7dc0fe3 ↗) - zero_trust_dlp_predefined_entry: Support
upload_status(7dc0fe3 ↗) - zero_trust_gateway_policy: Support
forensic_copy(5741fd0 ↗) - zero_trust_list: Support additional types (category, location, device) (5741fd0 ↗)
- access_rules: Add validation to prevent state drift. Ideally, we'd use Semantic Equality but since that isn't an option, this will remove a foot-gun. (4457791 ↗)
- cloudflare_pages_project: Addressing drift issues (6edffcf ↗) (3db318e ↗)
- cloudflare_worker: Can be cleanly imported (4859b52 ↗)
- cloudflare_worker: Ensure clean imports (5b525bc ↗)
- list_items: Add validation for IP List items to avoid inconsistent state (b6733dc ↗)
- zero_trust_access_application: Remove all conditions from sweeper (3197f1a ↗)
- spectrum_application: Map missing fields during spectrum resource import (#6495 ↗) (ddb4e72 ↗)
We suggest waiting to migrate to v5 while we work on stabilization. This helps with avoiding any blocking issues while the Terraform resources are actively being stabilized ↗. We will be releasing a new migration tool in March 2026 to help support v4 to v5 transitions for our most popular resources.
TanStack Start ↗ apps can now prerender routes to static HTML at build time with access to build time environment variables and bindings, and serve them as static assets. To enable prerendering, configure the
prerenderoption of the TanStack Start plugin in your Vite config:vite.config.ts import { defineConfig } from "vite";import { cloudflare } from "@cloudflare/vite-plugin";import { tanstackStart } from "@tanstack/react-start/plugin/vite";export default defineConfig({plugins: [cloudflare({ viteEnvironment: { name: "ssr" } }),tanstackStart({prerender: {enabled: true,},}),],});This feature requires
@tanstack/react-startv1.138.0 or later. See the TanStack Start framework guide for more details.
The Overview tab is now the default view in AI Crawl Control. The previous default view with controls for individual AI crawlers is available in the Crawlers tab.
- Executive summary — Monitor total requests, volume change, most common status code, most popular path, and high-volume activity
- Operator grouping — Track crawlers by their operating companies (OpenAI, Microsoft, Google, ByteDance, Anthropic, Meta)
- Customizable filters — Filter your snapshot by date range, crawler, operator, hostname, or path
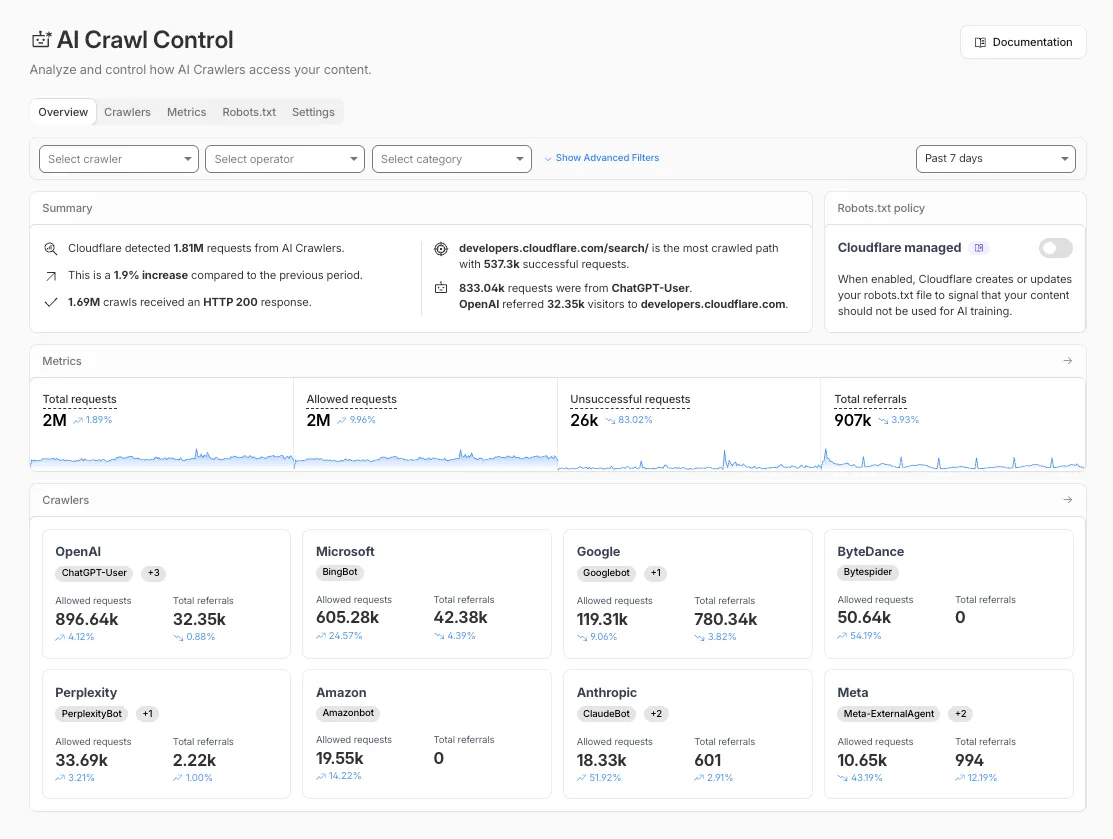
- Log in to the Cloudflare dashboard and select your account and domain.
- Go to AI Crawl Control, where the Overview tab opens by default with your activity snapshot.
- Use filters to customize your view by date range, crawler, operator, hostname, or path.
- Navigate to the Crawlers tab to manage controls for individual crawlers.
Learn more about analyzing AI traffic and managing AI crawlers.
The cached/uncached classification logic used in Zone Overview analytics has been updated to improve accuracy.
Previously, requests were classified as "cached" based on an overly broad condition that included blocked 403 responses, Snippets requests, and other non-cache request types. This caused inflated cache hit ratios — in some cases showing near-100% cached — and affected approximately 15% of requests classified as cached in rollups.
The condition has been removed from the Zone Overview page. Cached/uncached classification now aligns with the heuristics used in HTTP Analytics, so only requests genuinely served from cache are counted as cached.
What changed:
- Zone Overview — Cache ratios now reflect actual cache performance.
- HTTP Analytics — No change. HTTP Analytics already used the correct classification logic.
- Historical data — This fix applies to new requests only. Previously logged data is not retroactively updated.
R2 Data Catalog now supports automatic snapshot expiration for Apache Iceberg tables.
In Apache Iceberg, a snapshot is metadata that represents the state of a table at a given point in time. Every mutation creates a new snapshot which enable powerful features like time travel queries and rollback capabilities but will accumulate over time.
Without regular cleanup, these accumulated snapshots can lead to:
- Metadata overhead
- Slower table operations
- Increased storage costs.
Snapshot expiration in R2 Data Catalog automatically removes old table snapshots based on your configured retention policy, improving performance and storage costs.
Terminal window # Enable catalog-level snapshot expiration# Expire snapshots older than 7 days, always retain at least 10 recent snapshotsnpx wrangler r2 bucket catalog snapshot-expiration enable my-bucket \--older-than-days 7 \--retain-last 10Snapshot expiration uses two parameters to determine which snapshots to remove:
--older-than-days: age threshold in days--retain-last: minimum snapshot count to retain
Both conditions must be met before a snapshot is expired, ensuring you always retain recent snapshots even if they exceed the age threshold.
This feature complements automatic compaction, which optimizes query performance by combining small data files into larger ones. Together, these automatic maintenance operations keep your Iceberg tables performant and cost-efficient without manual intervention.
To learn more about snapshot expiration and how to configure it, visit our table maintenance documentation or see how to manage catalogs.
This week's release focuses on improvements to existing detections to enhance coverage.
Key Findings
- Existing rule enhancements have been deployed to improve detection resilience against broad classes of web attacks and strengthen behavioral coverage.
Ruleset Rule ID Legacy Rule ID Description Previous Action New Action Comments Cloudflare Managed Ruleset N/A Atlassian Confluence - Code Injection - CVE:CVE-2021-26084 - Beta Log Block This rule is merged into the original rule "Atlassian Confluence - Code Injection - CVE:CVE-2021-26084" (ID: Cloudflare Managed Ruleset N/A PostgreSQL - SQLi - Copy - Beta Log Block This rule is merged into the original rule "PostgreSQL - SQLi - COPY" (ID: Cloudflare Managed Ruleset N/A Generic Rules - Command Execution - Body Log Disabled This is a new detection. Cloudflare Managed Ruleset N/A Generic Rules - Command Execution - Header Log Disabled This is a new detection. Cloudflare Managed Ruleset N/A Generic Rules - Command Execution - URI Log Disabled This is a new detection. Cloudflare Managed Ruleset N/A SQLi - Tautology - URI - Beta Log Block This rule is merged into the original rule "SQLi - Tautology - URI" (ID: Cloudflare Managed Ruleset N/A SQLi - WaitFor Function - Beta Log Block This rule is merged into the original rule "SQLi - WaitFor Function" (ID: Cloudflare Managed Ruleset N/A SQLi - AND/OR Digit Operator Digit 2 - Beta Log Block This rule is merged into the original rule "SQLi - AND/OR Digit Operator Digit" (ID: Cloudflare Managed Ruleset N/A SQLi - Equation 2 - Beta Log Block This rule is merged into the original rule "SQLi - Equation" (ID:
Workers for Platforms lets you build multi-tenant platforms on Cloudflare Workers, allowing your end users to deploy and run their own code on your platform. It's designed for anyone building an AI vibe coding platform, e-commerce platform, website builder, or any product that needs to securely execute user-generated code at scale.
Previously, setting up Workers for Platforms required using the API. Now, the Workers for Platforms UI supports namespace creation, dispatch worker templates, and tag management, making it easier for Workers for Platforms customers to build and manage multi-tenant platforms directly from the Cloudflare dashboard.
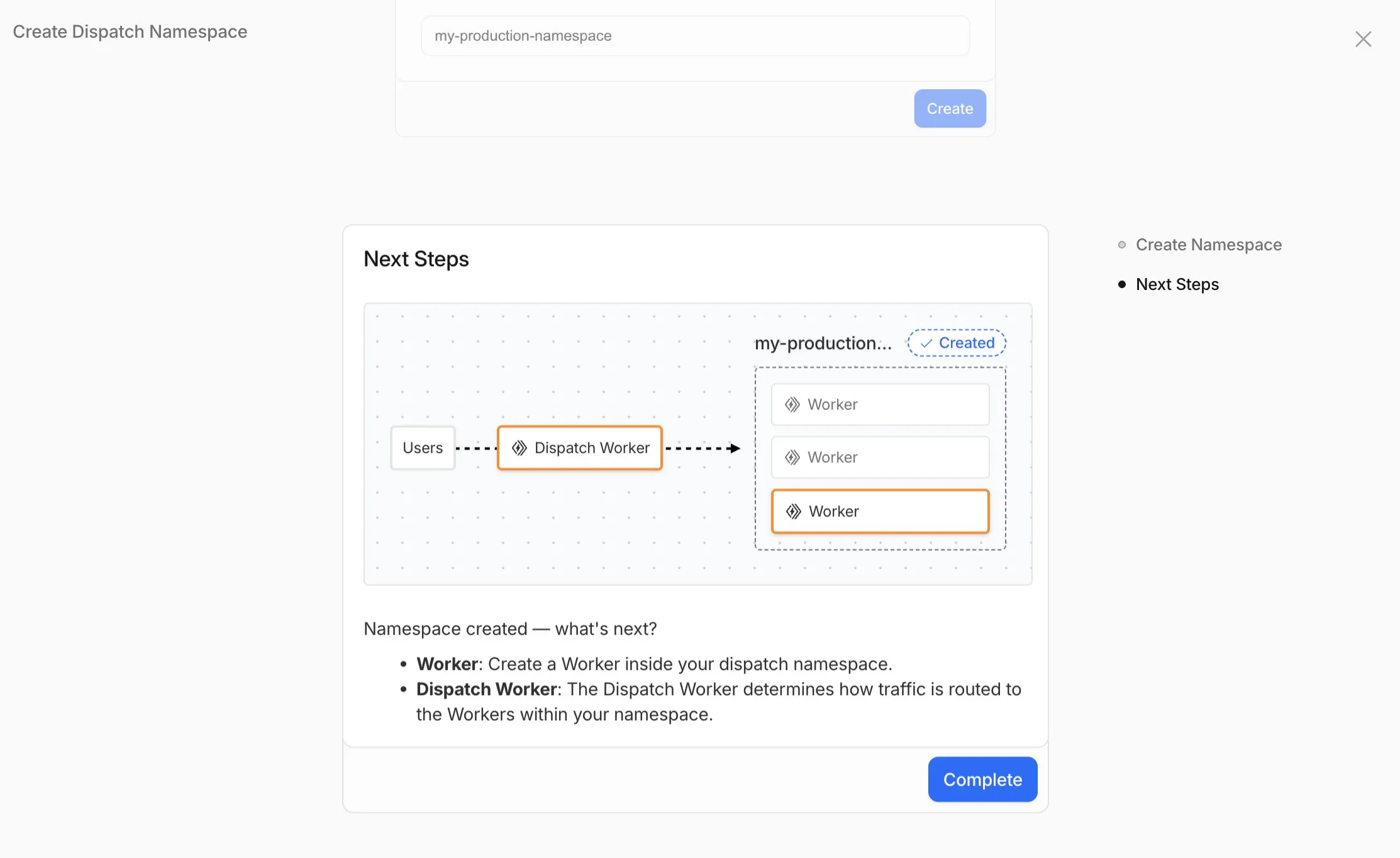
- Namespace Management: You can now create and configure dispatch namespaces directly within the dashboard to start a new platform setup.
- Dispatch Worker Templates: New Dispatch Worker templates allow you to quickly define how traffic is routed to individual Workers within your namespace. Refer to the Dynamic Dispatch documentation for more examples.
- Tag Management: You can now set and update tags on User Workers, making it easier to group and manage your Workers.
- Binding Visibility: Bindings attached to User Workers are now visible directly within the User Worker view.
- Deploy Vibe Coding Platform in one-click: Deploy a reference implementation of an AI vibe coding platform directly from the dashboard. Powered by the Cloudflare's VibeSDK ↗, this starter kit integrates with Workers for Platforms to handle the deployment of AI-generated projects at scale.
To get started, go to Workers for Platforms under Compute & AI in the Cloudflare dashboard ↗.
We've published build image policies for Workers Builds and Cloudflare Pages, which establish:
- Minor version updates: We typically update preinstalled software to the latest available minor version without notice. For tools that don't follow semantic versioning (e.g., Bun or Hugo), we provide 3 months’ notice.
- Major version updates: Before preinstalled software reaches end-of-life, we update to the next stable LTS version with 3 months’ notice.
- Build image version deprecation (Pages only): We provide 6 months’ notice before deprecation. Projects on v1 or v2 will be automatically moved to v3 on their specified deprecation dates.
To prepare for updates, monitor the Cloudflare Changelog ↗, dashboard notifications, and email. You can also override default versions to maintain specific versions.
Wrangler now includes a new
wrangler auth tokencommand that retrieves your current authentication token or credentials for use with other tools and scripts.Terminal window wrangler auth tokenThe command returns whichever authentication method is currently configured, in priority order: API token from
CLOUDFLARE_API_TOKEN, or OAuth token fromwrangler login(automatically refreshed if expired).Use the
--jsonflag to get structured output including the token type:Terminal window wrangler auth token --jsonThe JSON output includes the authentication type:
// API token{ "type": "api_token", "token": "..." }// OAuth token{ "type": "oauth", "token": "..." }// API key/email (only available with --json){ "type": "api_key", "key": "...", "email": "..." }API key/email credentials from
CLOUDFLARE_API_KEYandCLOUDFLARE_EMAILrequire the--jsonflag since this method uses two values instead of a single token.
Zero Trust has again upgraded its Shadow IT analytics, providing you with unprecedented visibility into your organizations use of SaaS tools. With this dashboard, you can review who is using an application and volumes of data transfer to the application.
With this update, you can review data transfer metrics at the domain level, rather than just the application level, providing more granular insight into your data transfer patterns.
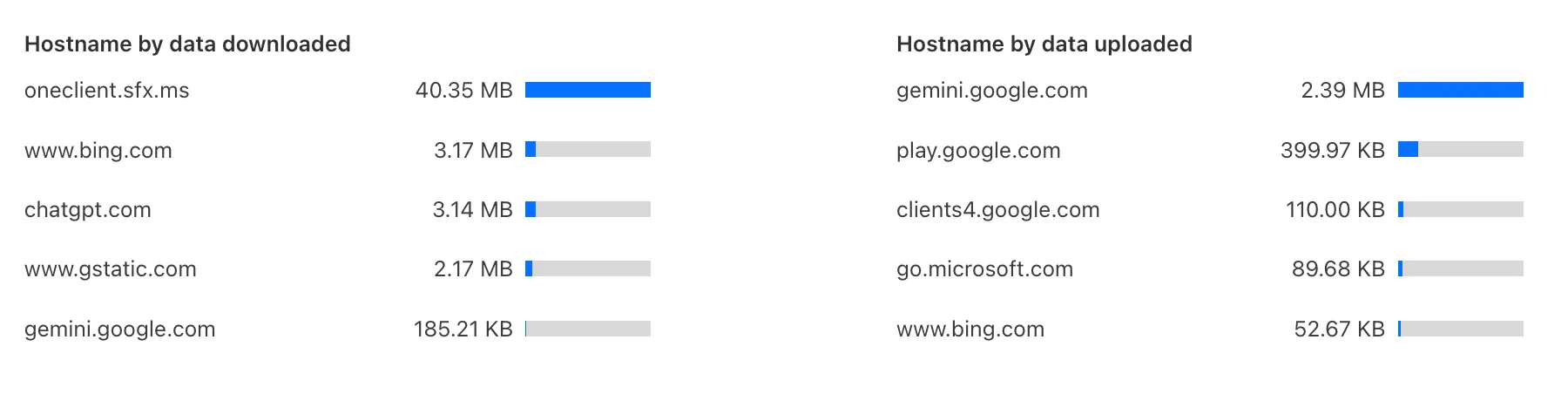
These metrics can be filtered by all available filters on the dashboard, including user, application, or content category.
Both the analytics and policies are accessible in the Cloudflare Zero Trust dashboard ↗, empowering organizations with better visibility and control.
You can now duplicate specific Cloudflare One resources with a single click from the dashboard.
Initially supported resources:
- Access Applications
- Access Policies
- Gateway Policies
To try this out, simply click on the overflow menu (⋮) from the resource table and click Duplicate. We will continue to add the Duplicate action for resources throughout 2026.
The
@cloudflare/vitest-pool-workerspackage now supports thectx.exportsAPI, allowing you to access your Worker's top-level exports during tests.You can access
ctx.exportsin unit tests by callingcreateExecutionContext():TypeScript import { createExecutionContext } from "cloudflare:test";import { it, expect } from "vitest";it("can access ctx.exports", async () => {const ctx = createExecutionContext();const result = await ctx.exports.MyEntryPoint.myMethod();expect(result).toBe("expected value");});Alternatively, you can import
exportsdirectly fromcloudflare:workers:TypeScript import { exports } from "cloudflare:workers";import { it, expect } from "vitest";it("can access imported exports", async () => {const result = await exports.MyEntryPoint.myMethod();expect(result).toBe("expected value");});See the context-exports fixture ↗ for a complete example.
Wrangler now supports automatic configuration for popular web frameworks in experimental mode, making it even easier to deploy to Cloudflare Workers.
Previously, if you wanted to deploy an application using a popular web framework like Next.js or Astro, you had to follow tutorials to set up your application for deployment to Cloudflare Workers. This usually involved creating a Wrangler file, installing adapters, or changing configuration options.
Now
wrangler deploydoes this for you. Starting with Wrangler 4.55, you can usenpx wrangler deploy --x-autoconfigin the directory of any web application using one of the supported frameworks. Wrangler will then proceed to configure and deploy it to your Cloudflare account.You can also configure your application without deploying it by using the new
npx wrangler setupcommand. This enables you to easily review what changes we are making so your application is ready for Cloudflare Workers.The following application frameworks are supported starting today:
- Next.js
- Astro
- Nuxt
- TanStack Start
- SolidStart
- React Router
- SvelteKit
- Docusaurus
- Qwik
- Analog
Automatic configuration also supports static sites by detecting the assets directory and build command. From a single index.html file to the output of a generator like Jekyll or Hugo, you can just run
npx wrangler deploy --x-autoconfigto upload to Cloudflare.We're really excited to bring you automatic configuration so you can do more with Workers. Please let us know if you run into challenges using this experimentally. We’ve opened a GitHub discussion ↗ and would love to hear your feedback.
A new Rules of Durable Objects guide is now available, providing opinionated best practices for building effective Durable Objects applications. This guide covers design patterns, storage strategies, concurrency, and common anti-patterns to avoid.
Key guidance includes:
- Design around your "atom" of coordination — Create one Durable Object per logical unit (chat room, game session, user) instead of a global singleton that becomes a bottleneck.
- Use SQLite storage with RPC methods — SQLite-backed Durable Objects with typed RPC methods provide the best developer experience and performance.
- Understand input and output gates — Learn how Cloudflare's runtime prevents data races by default, how write coalescing works, and when to use
blockConcurrencyWhile(). - Leverage Hibernatable WebSockets — Reduce costs for real-time applications by allowing Durable Objects to sleep while maintaining WebSocket connections.
The testing documentation has also been updated with modern patterns using
@cloudflare/vitest-pool-workers, including examples for testing SQLite storage, alarms, and direct instance access:test/counter.test.js import { env, runDurableObjectAlarm } from "cloudflare:test";import { it, expect } from "vitest";it("can test Durable Objects with isolated storage", async () => {const stub = env.COUNTER.getByName("test");// Call RPC methods directly on the stubawait stub.increment();expect(await stub.getCount()).toBe(1);// Trigger alarms immediately without waitingawait runDurableObjectAlarm(stub);});test/counter.test.ts import { env, runDurableObjectAlarm } from "cloudflare:test";import { it, expect } from "vitest";it("can test Durable Objects with isolated storage", async () => {const stub = env.COUNTER.getByName("test");// Call RPC methods directly on the stubawait stub.increment();expect(await stub.getCount()).toBe(1);// Trigger alarms immediately without waitingawait runDurableObjectAlarm(stub);});
Storage billing for SQLite-backed Durable Objects will be enabled in January 2026, with a target date of January 7, 2026 (no earlier).
To view your SQLite storage usage, go to the Durable Objects page
Go to Durable ObjectsIf you do not want to incur costs, please take action such as optimizing queries or deleting unnecessary stored data in order to reduce your SQLite storage usage ahead of the January 7th target. Only usage on and after the billing target date will incur charges.
Developers on the Workers Paid plan with Durable Object's SQLite storage usage beyond included limits will incur charges according to SQLite storage pricing announced in September 2024 with the public beta ↗. Developers on the Workers Free plan will not be charged.
Compute billing for SQLite-backed Durable Objects has been enabled since the initial public beta. SQLite-backed Durable Objects currently incur charges for requests and duration, and no changes are being made to compute billing.
For more information about SQLite storage pricing and limits, refer to the Durable Objects pricing documentation.
R2 SQL now supports aggregation functions,
GROUP BY,HAVING, along with schema discovery commands to make it easy to explore your data catalog.You can now perform aggregations on Apache Iceberg tables in R2 Data Catalog using standard SQL functions including
COUNT(*),SUM(),AVG(),MIN(), andMAX(). Combine these withGROUP BYto analyze data across dimensions, and useHAVINGto filter aggregated results.-- Calculate average transaction amounts by departmentSELECT department, COUNT(*), AVG(total_amount)FROM my_namespace.sales_dataWHERE region = 'North'GROUP BY departmentHAVING COUNT(*) > 50ORDER BY AVG(total_amount) DESC-- Find high-value departmentsSELECT department, SUM(total_amount)FROM my_namespace.sales_dataGROUP BY departmentHAVING SUM(total_amount) > 50000New metadata commands make it easy to explore your data catalog and understand table structures:
SHOW DATABASESorSHOW NAMESPACES- List all available namespacesSHOW TABLES IN namespace_name- List tables within a namespaceDESCRIBE namespace_name.table_name- View table schema and column types
Terminal window ❯ npx wrangler r2 sql query "{ACCOUNT_ID}_{BUCKET_NAME}" "DESCRIBE default.sales_data;"⛅️ wrangler 4.54.0─────────────────────────────────────────────┌──────────────────┬────────────────┬──────────┬─────────────────┬───────────────┬───────────────────────────────────────────────────────────────────────────────────────────────────┐│ column_name │ type │ required │ initial_default │ write_default │ doc │├──────────────────┼────────────────┼──────────┼─────────────────┼───────────────┼───────────────────────────────────────────────────────────────────────────────────────────────────┤│ sale_id │ BIGINT │ false │ │ │ Unique identifier for each sales transaction │├──────────────────┼────────────────┼──────────┼─────────────────┼───────────────┼───────────────────────────────────────────────────────────────────────────────────────────────────┤│ sale_timestamp │ TIMESTAMPTZ │ false │ │ │ Exact date and time when the sale occurred (used for partitioning) │├──────────────────┼────────────────┼──────────┼─────────────────┼───────────────┼───────────────────────────────────────────────────────────────────────────────────────────────────┤│ department │ TEXT │ false │ │ │ Product department (8 categories: Electronics, Beauty, Home, Toys, Sports, Food, Clothing, Books) │├──────────────────┼────────────────┼──────────┼─────────────────┼───────────────┼───────────────────────────────────────────────────────────────────────────────────────────────────┤│ category │ TEXT │ false │ │ │ Product category grouping (4 categories: Premium, Standard, Budget, Clearance) │├──────────────────┼────────────────┼──────────┼─────────────────┼───────────────┼───────────────────────────────────────────────────────────────────────────────────────────────────┤│ region │ TEXT │ false │ │ │ Geographic sales region (5 regions: North, South, East, West, Central) │├──────────────────┼────────────────┼──────────┼─────────────────┼───────────────┼───────────────────────────────────────────────────────────────────────────────────────────────────┤│ product_id │ INT │ false │ │ │ Unique identifier for the product sold │├──────────────────┼────────────────┼──────────┼─────────────────┼───────────────┼───────────────────────────────────────────────────────────────────────────────────────────────────┤│ quantity │ INT │ false │ │ │ Number of units sold in this transaction (range: 1-50) │├──────────────────┼────────────────┼──────────┼─────────────────┼───────────────┼───────────────────────────────────────────────────────────────────────────────────────────────────┤│ unit_price │ DECIMAL(10, 2) │ false │ │ │ Price per unit in dollars (range: $5.00-$500.00) │├──────────────────┼────────────────┼──────────┼─────────────────┼───────────────┼───────────────────────────────────────────────────────────────────────────────────────────────────┤│ total_amount │ DECIMAL(10, 2) │ false │ │ │ Total sale amount before tax (quantity × unit_price with discounts applied) │├──────────────────┼────────────────┼──────────┼─────────────────┼───────────────┼───────────────────────────────────────────────────────────────────────────────────────────────────┤│ discount_percent │ INT │ false │ │ │ Discount percentage applied to this sale (0-50%) │├──────────────────┼────────────────┼──────────┼─────────────────┼───────────────┼───────────────────────────────────────────────────────────────────────────────────────────────────┤│ tax_amount │ DECIMAL(10, 2) │ false │ │ │ Tax amount collected on this sale │├──────────────────┼────────────────┼──────────┼─────────────────┼───────────────┼───────────────────────────────────────────────────────────────────────────────────────────────────┤│ profit_margin │ DECIMAL(10, 2) │ false │ │ │ Profit margin on this sale as a decimal percentage │├──────────────────┼────────────────┼──────────┼─────────────────┼───────────────┼───────────────────────────────────────────────────────────────────────────────────────────────────┤│ customer_id │ INT │ false │ │ │ Unique identifier for the customer who made the purchase │├──────────────────┼────────────────┼──────────┼─────────────────┼───────────────┼───────────────────────────────────────────────────────────────────────────────────────────────────┤│ is_online_sale │ BOOLEAN │ false │ │ │ Boolean flag indicating if sale was made online (true) or in-store (false) │├──────────────────┼────────────────┼──────────┼─────────────────┼───────────────┼───────────────────────────────────────────────────────────────────────────────────────────────────┤│ sale_date │ DATE │ false │ │ │ Calendar date of the sale (extracted from sale_timestamp) │└──────────────────┴────────────────┴──────────┴─────────────────┴───────────────┴───────────────────────────────────────────────────────────────────────────────────────────────────┘Read 0 B across 0 files from R2On average, 0 B / sTo learn more about the new aggregation capabilities and schema discovery commands, check out the SQL reference. If you're new to R2 SQL, visit our getting started guide to begin querying your data.
Cloudflare Logpush now supports SentinelOne as a native destination.
Logs from Cloudflare can be sent to SentinelOne AI SIEM ↗ via Logpush. The destination can be configured through the Logpush UI in the Cloudflare dashboard or by using the Logpush API.
For more information, refer to the Destination Configuration documentation.
This emergency release introduces rules for CVE-2025-55183 and CVE-2025-55184, targeting server-side function exposure and resource-exhaustion patterns, respectively.
Key Findings
Added coverage for Leaking Server Functions (CVE-2025-55183) and React Function DoS detection (CVE-2025-55184).
Impact
These updates strengthen protection for server-function abuse techniques (CVE-2025-55183, CVE-2025-55184) that may expose internal logic or disrupt application availability.
Ruleset Rule ID Legacy Rule ID Description Previous Action New Action Comments Cloudflare Managed Ruleset N/A React - Leaking Server Functions - CVE:CVE-2025-55183 N/A Block This was labeled as Generic - Server Function Source Code Exposure. Cloudflare Free Ruleset N/A React - Leaking Server Functions - CVE:CVE-2025-55183 N/A Block This was labeled as Generic - Server Function Source Code Exposure. Cloudflare Managed Ruleset N/A React - DoS - CVE:CVE-2025-55184 N/A Disabled This was labeled as Generic – Server Function Resource Exhaustion.
Pay Per Crawl is introducing enhancements for both AI crawler operators and site owners, focusing on programmatic discovery, flexible pricing models, and granular configuration control.
A new authenticated API endpoint allows verified crawlers to programmatically discover domains participating in Pay Per Crawl. Crawlers can use this to build optimized crawl queues, cache domain lists, and identify new participating sites. This eliminates the need to discover payable content through trial requests.
The API endpoint is
GET https://crawlers-api.ai-audit.cfdata.org/charged_zonesand requires Web Bot Auth authentication. Refer to Discover payable content for authentication steps, request parameters, and response schema.Payment headers (
crawler-exact-priceorcrawler-max-price) must now be included in the Web Bot Authsignature-inputheader components. This security enhancement prevents payment header tampering, ensures authenticated payment intent, validates crawler identity with payment commitment, and protects against replay attacks with modified pricing. Crawlers must add their payment header to the list of signed components when constructing the signature-input header.Pay Per Crawl error responses now include a new
crawler-errorheader with 11 specific error codes for programmatic handling. Error response bodies remain unchanged for compatibility. These codes enable robust error handling, automated retry logic, and accurate spending tracking.Site owners can now offer free access to specific pages like homepages, navigation, or discovery pages while charging for other content. Create a Configuration Rule in Rules > Configuration Rules, set your URI pattern using wildcard, exact, or prefix matching on the URI Full field, and enable the Disable Pay Per Crawl setting. When disabled for a URI pattern, crawler requests pass through without blocking or charging.
Some paths are always free to crawl. These paths are:
/robots.txt,/sitemap.xml,/security.txt,/.well-known/security.txt,/crawlers.json.AI crawler operators: Discover payable content | Crawl pages
Site owners: Advanced configuration
This additional week's emergency release introduces improvements to our existing rule for React – Remote Code Execution – CVE-2025-55182 - 2, along with two new generic detections covering server-side function exposure and resource-exhaustion patterns.
Key Findings
Enhanced detection logic for React – RCE – CVE-2025-55182, added Generic – Server Function Source Code Exposure, and added Generic – Server Function Resource Exhaustion.
Impact
These updates strengthen protection against React RCE exploitation attempts and broaden coverage for common server-function abuse techniques that may expose internal logic or disrupt application availability.
Ruleset Rule ID Legacy Rule ID Description Previous Action New Action Comments Cloudflare Managed Ruleset N/A React - Remote Code Execution - CVE:CVE-2025-55182 - 2 N/A Block This is an improved detection. Cloudflare Free Ruleset N/A React - Remote Code Execution - CVE:CVE-2025-55182 - 2 N/A Block This is an improved detection. Cloudflare Managed Ruleset N/A Generic - Server Function Source Code Exposure N/A Block This is a new detection. Cloudflare Free Ruleset N/A Generic - Server Function Source Code Exposure N/A Block This is a new detection. Cloudflare Managed Ruleset N/A Generic - Server Function Resource Exhaustion N/A Disabled This is a new detection.
A new Beta release for the Windows WARP client is now available on the beta releases downloads page.
This release contains minor fixes and improvements.
Changes and improvements
- The Local Domain Fallback feature has been fixed for devices running WARP client version 2025.4.929.0 and newer. Previously, these devices could experience failures with Local Domain Fallback unless a fallback server was explicitly configured. This configuration is no longer a requirement for the feature to function correctly.
- Proxy mode now supports transparent HTTP proxying in addition to CONNECT-based proxying.
- Fixed an issue where sending large messages to the WARP daemon by Inter-Process Communication (IPC) could cause WARP to crash and result in service interruptions.
Known issues
For Windows 11 24H2 users, Microsoft has confirmed a regression that may lead to performance issues like mouse lag, audio cracking, or other slowdowns. Cloudflare recommends users experiencing these issues upgrade to a minimum Windows 11 24H2 KB5062553 or higher for resolution.
Devices with KB5055523 installed may receive a warning about
Win32/ClickFix.ABAbeing present in the installer. To resolve this false positive, update Microsoft Security Intelligence to version 1.429.19.0 or later.DNS resolution may be broken when the following conditions are all true:
- WARP is in Secure Web Gateway without DNS filtering (tunnel-only) mode.
- A custom DNS server address is configured on the primary network adapter.
- The custom DNS server address on the primary network adapter is changed while WARP is connected.
To work around this issue, reconnect the WARP client by toggling off and back on.
A new Beta release for the macOS WARP client is now available on the beta releases downloads page.
This release contains minor fixes and improvements.
Changes and improvements
- The Local Domain Fallback feature has been fixed for devices running WARP client version 2025.4.929.0 and newer. Previously, these devices could experience failures with Local Domain Fallback unless a fallback server was explicitly configured. This configuration is no longer a requirement for the feature to function correctly.
- Proxy mode now supports transparent HTTP proxying in addition to CONNECT-based proxying.
Python Workers now feature improved cold start performance, reducing initialization time for new Worker instances. This improvement is particularly noticeable for Workers with larger dependency sets or complex initialization logic.
Every time you deploy a Python Worker, a memory snapshot is captured after the top level of the Worker is executed. This snapshot captures all imports, including package imports that are often costly to load. The memory snapshot is loaded when the Worker is first started, avoiding the need to reload the Python runtime and all dependencies on each cold start.
We set up a benchmark that imports common packages (httpx ↗, fastapi ↗ and pydantic ↗) to see how Python Workers stack up against other platforms:
Platform Mean Cold Start (ms) Cloudflare Python Workers 1027 AWS Lambda 2502 Google Cloud Run 3069 These benchmarks run continuously. You can view the results and the methodology on our benchmark page ↗.
In additional testing, we have found that without any memory snapshot, the cold start for this benchmark takes around 10 seconds, so this change improves cold start performance by roughly a factor of 10.
To get started with Python Workers, check out our Python Workers overview.
We are introducing a brand new tool called Pywrangler, which simplifies package management in Python Workers by automatically installing Workers-compatible Python packages into your project.
With Pywrangler, you specify your Worker's Python dependencies in your
pyproject.tomlfile:[project]name = "python-beautifulsoup-worker"version = "0.1.0"description = "A simple Worker using beautifulsoup4"requires-python = ">=3.12"dependencies = ["beautifulsoup4"][dependency-groups]dev = ["workers-py","workers-runtime-sdk"]You can then develop and deploy your Worker using the following commands:
Terminal window uv run pywrangler devuv run pywrangler deployPywrangler automatically downloads and vendors the necessary packages for your Worker, and these packages are bundled with the Worker when you deploy.
Consult the Python packages documentation for full details on Pywrangler and Python package management in Workers.